The choice that defines this release is what isn’t in it.
We did not bundle a vector database. We did not ship an embedding pipeline. We did not build an ingestion queue. Today, May 20, 2026, PressBot’s new External Knowledge feature is live on both the Free and Pro plans, and the entire design starts from a single constraint: we never touch your corpus.
Most WordPress RAG plugins shipping right now are racing to own the corpus. They create custom tables, crawl your sitemap, chunk your documents, store your embeddings, and rank your results inside their own infrastructure. That single architectural decision quietly locks you into one vendor’s storage format, one vendor’s ranking logic, and one vendor’s pricing curve. Some teams have reported spending eight times more than expected on vector database infrastructure after extrapolating from prototype-tier pricing. Once a plugin owns your embeddings, changing providers means retraining everything, because vector formats differ between providers. That’s not a migration. That’s a rebuild.
PressBot took the opposite default: bring your retriever. Pinecone, Weaviate, pgvector, Elasticsearch, Qdrant, or something custom you built last quarter. We handle the WordPress chat layer. The contract between the two sides is plain HTTPS + JSON. No SDK. No proprietary format. No migration when you decide to swap retrievers next year.
What External Knowledge Actually Does
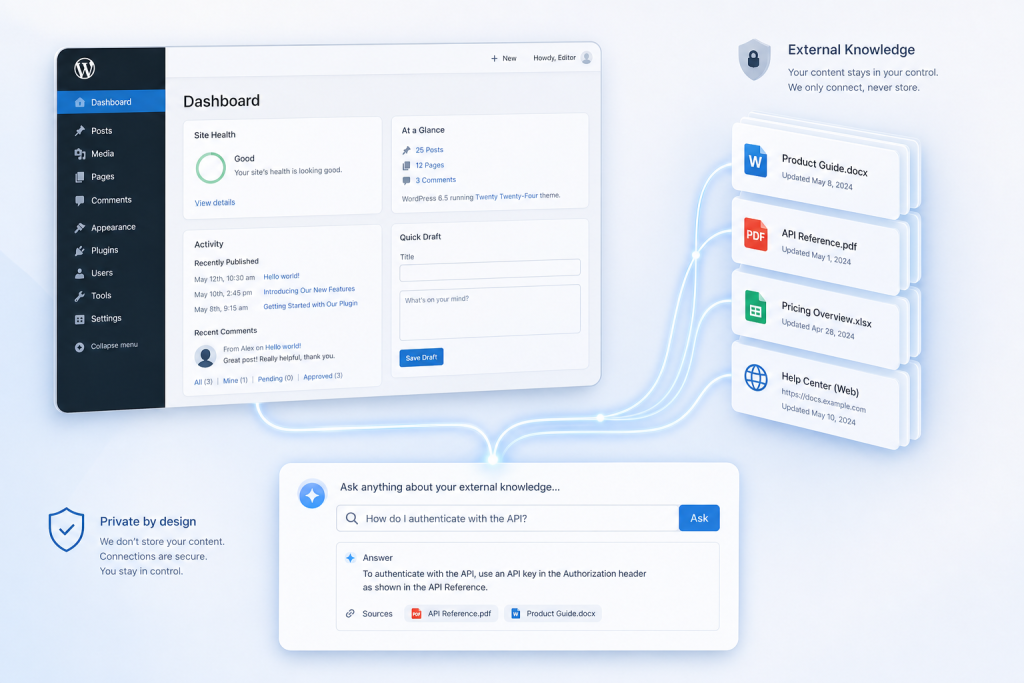
Here’s the concrete flow. A visitor asks a question in your public chatbot. PressBot evaluates whether the question needs external context and decides to call a visitor-safe tool called search_knowledge_corpus. That tool POSTs the visitor’s query to the retriever endpoint the site owner configured in PressBot settings. The request is simple: a JSON body with the query string, an optional scope filter, and a result count limit.
Your retriever does what it does best. It returns ranked matches, each carrying a source title, a URL or path, a relevance score, a timestamp, and a text snippet. PressBot normalizes those matches, selects the most relevant ones, and grounds its answer with inline citations the visitor can click. The visitor sees a well-sourced response. Your retriever stays where it is. PressBot never stores, copies, or re-indexes any of it.
A practical example: say you run a technical education site. Your course transcripts live in object storage, indexed into a Pinecone namespace. A visitor asks your chatbot, “How do I configure webhook retries in the Advanced API module?” PressBot calls your Pinecone endpoint, gets back three ranked transcript segments with lesson titles and URLs, and answers the question with citations linking directly to the relevant course pages. The visitor gets a grounded answer. Your corpus never left your infrastructure.
Safety, Briefly
The retriever connection uses encrypted bearer-token authentication, stored at rest with WordPress salts. Retrieval is bounded: query length, scope, result count, response size, and match text and URL caps are all enforced before the request leaves your site. Streaming is UTF-8 safe, so Spanish accents, CJK characters, and emoji survive the round trip without corruption.
Separation of Concerns Is a Customer-Protection Decision
This is not just an engineering style preference. The corpus is the site owner’s asset. Any plugin that swallows it is selling convenience and shipping a lock-in. WP Engine’s new VectorDB tells customers they “do not need to manage custom connectors or external pipelines.” That pitch sounds helpful right up until you need to leave. In 18 months, “does it own my corpus?” will be a disqualifying question for any AI WordPress plugin, the same way “is it actively maintained?” became one in 2022. We’d rather be early on the right side of that line than late.
Who This Is For
External Knowledge is built for teams whose real knowledge already lives outside WordPress. Transcripts in object storage. Product manuals on a documentation site. Course archives behind a login wall. Research papers in a vector store. Internal wikis that will never be WordPress posts. If your entire corpus already lives in wp_posts, the free PressBot chatbot already answers from that content and you don’t need this feature.
The audience we had in mind: WordPress site owners with corpora living elsewhere, agencies building knowledge-grounded chatbots for clients who already have retrieval infrastructure, and plugin builders watching the architectural patterns settle before committing to a stack. If you’ve already invested in Pinecone, pgvector, Weaviate, or Elastic, External Knowledge meets you where you are instead of asking you to start over inside WordPress.
What’s Next
The feature is live now. Every PressBot Free and Pro plan, from the single-site $99/year tier through Agency, includes External Knowledge at no additional cost.
We put together a full walkthrough at /wordpress-rag-chatbot/ with an animated retrieval diorama showing the request/response cycle, a live chat demo you can test against a real retriever, and the complete request/response contract so your team can evaluate the integration before committing. If you’re already on Pro, the feature is waiting in your PressBot settings. If you’re on the free plan and this is the feature you’ve been waiting for, the upgrade path is at /pro/#pricing.
Your corpus. Your retriever. Your infrastructure. We just made it answer visitor questions.